
 bilibili
bilibili论文解读Attention Is All You Need
Published:
Google提出的语言模型Transformer,抛弃了传统的CNN和RNN,整个网络结构完全是由Attention机制组成。
动机
传统词向量训练所有词无论在哪个句子中的哪个位置,其词向量都是固定的,不能够表达句子以及其context的含义。
RNN(或者LSTM,GRU等)的计算限制为是顺序的,也就是说RNN相关算法只能从向右依次计算或者从右向左依次计算,这种机制带来了两个问题:
时间片t的计算依赖t-1时刻的计算结果,这样限制了模型的并行能力;
顺序计算的过程中信息会丢失,尽管LSTM等门机制的结构一定程度上缓解了长期依赖的问题,但是对于特别长期的依赖现象,LSTM依旧无能为力。
框架
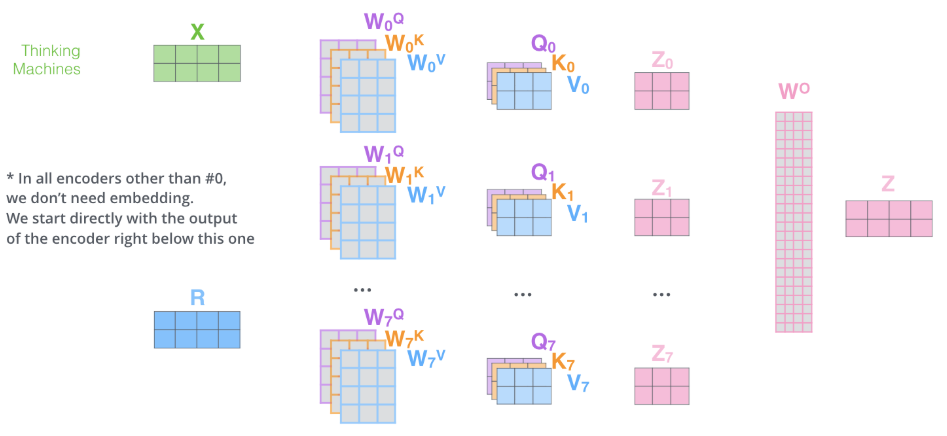
Transformer中抛弃了传统的CNN和RNN,整个网络结构完全是由Attention机制组成。更准确地讲,Transformer由且仅由self-Attenion和Feed Forward Neural Network组成。一个基于Transformer的可训练的神经网络可以通过堆叠Transformer的形式进行搭建,作者的实验是通过搭建编码器和解码器各6层,总共12层的Encoder-Decoder。
为了解决RNN的问题,transformer只用了attention机制,抛弃了传统RNN或CNN结构,将序列中的任意两个位置之间的距离是缩小为一个常量;其次它不是类似RNN的顺序结构,因此具有更好的并行性,符合现有的GPU框架。
Attention Network
attention起源于cv,在nlp领域最早用于seq2seq与机器翻译。在使用RNN作为encoder时每个token输出一个定长的hidden representation,如果要在decoder端根据整个句子的信息进行预测每个翻译出来的词的概率,仅通过encoder端最终输出的一个定长向量很难表达token之间的交互信息。attention解决了这个信息瓶颈问题 [1]:
An attention network maintains a set of hidden representations that scale with the size of the source. The model uses an internal inference step to perform a soft-selection over these representations. This method allows the model to maintain a variable-length memory and has shown to be crucially important for scaling systems for many tasks.
给定input序列 $x=[x_1, x_2, …, x_n]$,q是一个query,z是一个categorical variable,其取值是{1,…,n},代表根据q从x中选择相关的input。attention的目标就是根据q和x的信息生成一个上下文c。通过计算z的分布$z\sim p(z\rvert x, q)$,c可以写为期望的形式:
\[c=\mathbb{E}_{z\sim p(z\rvert x,q)}[f(x,z)]\]$f(x,z)$叫做annotation function,定义了x和z如何组合。具体来说,在一个基于RNN的机器翻译网络中,input x就是encoder RNN中每个节点的隐层,q就是decoder RNN中某个节点的隐层,z代表了翻译原文input的位置,也就是与当前decoder输入的词最相关的input的词。此时c的计算可写为:
\[c=\sum_{i=1}^np(z=i\rvert x,q)x_i\]其中$p(z=i\rvert x,q)=softmax(MLP(x_i; q))$。即根据q和x的关系来线性组合x。如果是self-attention的话,q就是x本身。
(图片来源:https://github.com/google/seq2seq)
Scaled Dot-Product Attention
Self-attention是一种attention机制,用来计算一个句子(中的token)的represetation,其包含了这个句子中token不同位置的关系。文章中引入了3个变量,Q,K,V。分别代表query,key,value。这3个变量都是由input embedding X与参数矩阵乘积得到的。
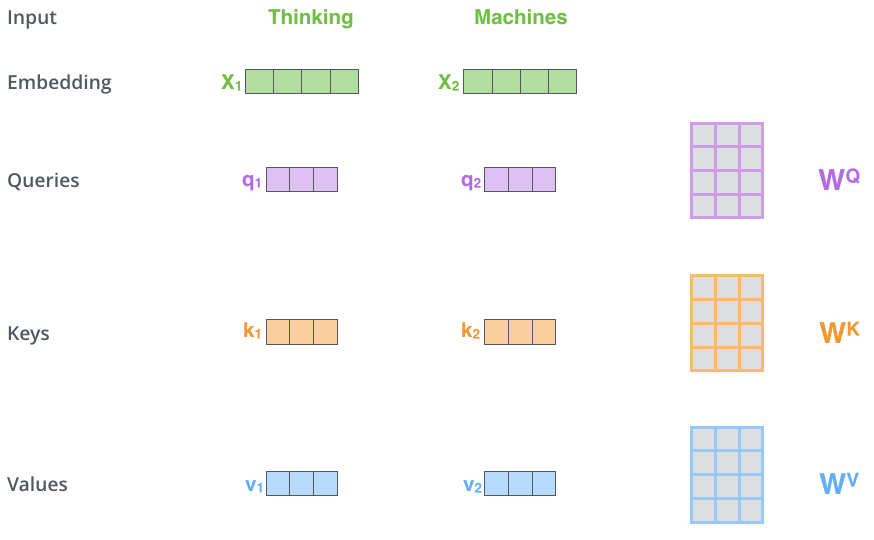
q代表当前中心词的attention representation,k表示周围词的attention representation。q与k相当于word2vec中的input & output embedding。k用来与q相乘得到attention score,得到词与词在句子中的相关性,v用来被softmax之后的attention score加权,加权和之后作为输出。
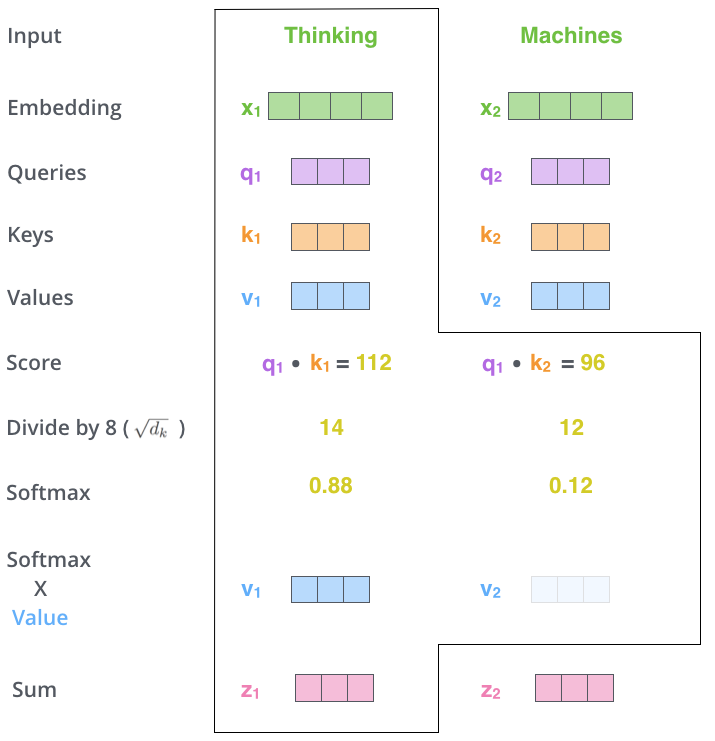
其中,由于矩阵乘法会改变数值量纲,所以在分母中添加$\sqrt{d_k}$。对比一下万宁画的skipgram:
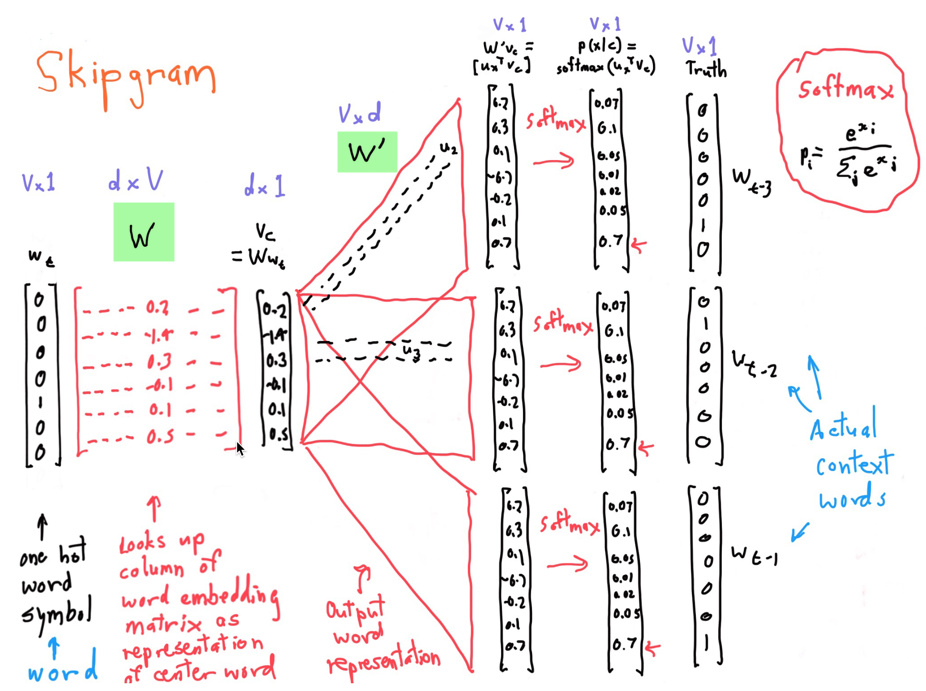
区别在于skipgram输入的是onehot,而transformer的input已经是词的embedding了。
Multi-head Attention
一组attention的权重参数只能够表达一种词与词之间的关系,在nlp任务中,一种关系可能不足以表达。所以通过配置多组attention权重矩阵,最后通过线性组合,来综合表达:
下图是一个2 head attention,从中可以看出,一个head关注到it所指代的东西”the animal”。另一个head侧重点在”tired”,表示该主语所对应的谓语。

Position-wise Feed-Forward Networks
每个attention的输出后面再接上一个权重共享的mlp,类似于RNN输出的h上面再接一层mlp作为输出。我觉得要加这个sub-layer的原因是再加一层激活函数,之前attention在qk内积之后加了softmax之后就再也没有非线性变换了。
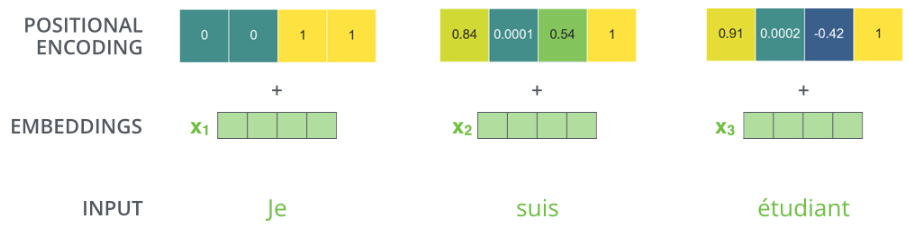
Positional Encoding
单纯使用attention没有办法将序列的位置信息融入表达。
\[PE_{(pos,2i)}=sin(pos/1000^{2i/d_{model}})\\PE_{(pos,2i+1)}=cos(pos/1000^{2i/d_{model}})\]其中pos是token的位置,i是第i维embedding。
用seq_len=256,emb_size=256,positional encoding(横轴是i,纵轴是pos):
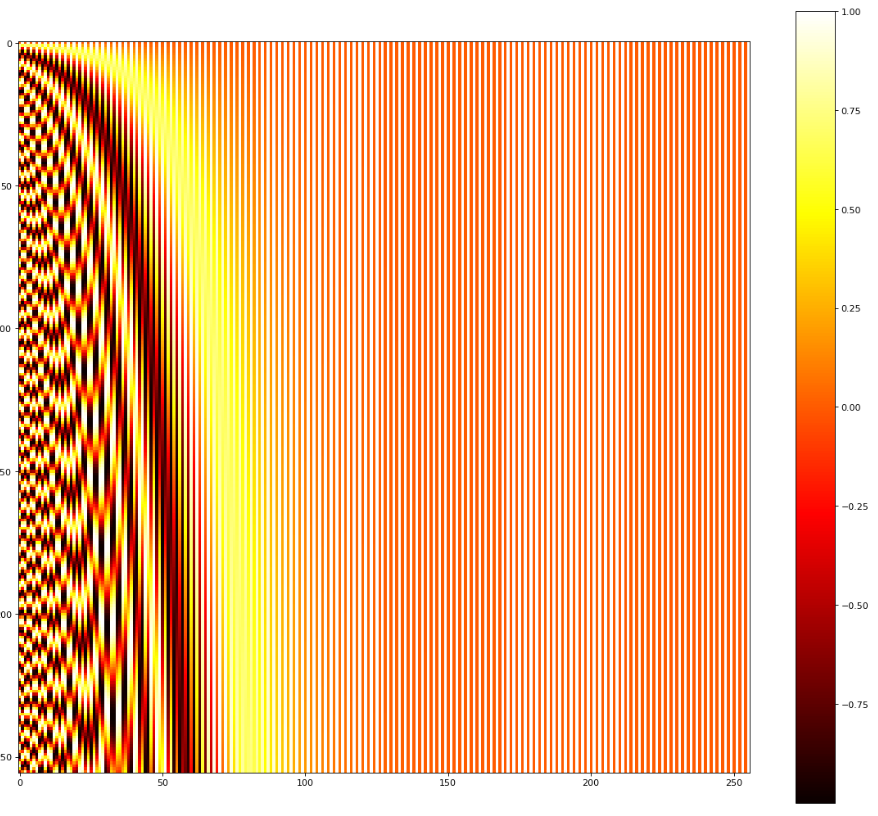
用positional encoding而不是positional embedding的原因是什么?
文中提到使用positional embedding的效果也差不多,但是依然使用positional encoding的原因是:
It may allow the model to extrapolate to sequence lengths longer than the ones encountered during training.
知乎评论:positional encoding看起来就像是magic number。
Model Architechture
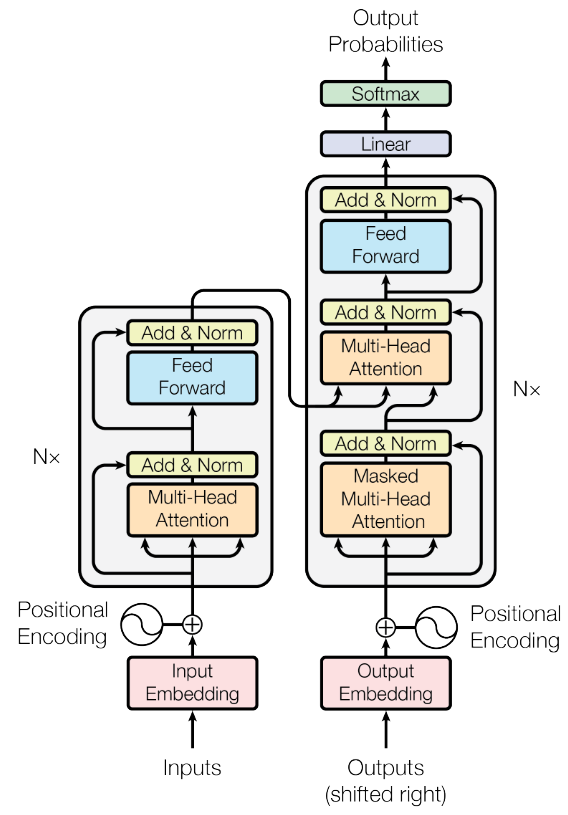
Residual connection
和图像中的residual使用目的一样,让底层的有效信息直接传递给高层。
Encoder and Decoder Stacks
encoder和decoder各6层stack。decoder中的结构和encoder略有不同,decoder中的第一个sublayer的multi-head attention加了一个mask,把位置i之后的给遮掉了,只让第i个query和它之前的token做attention,防止信息泄露。因为目标是预测下一个词,所以不能用到之后的词来预测自己。
Decoder中的两层multi-head attention
第一个是对output sequence中之前出现的词做attention加权。第二个是对input sequence中的词做attention加权,用第一层输出的q,和encoder输出的k,v做加权。(参考attention network小节中的图)
动图演示transformer如何翻译:
![]()
![]()
参考
[1] Kim, Y., Denton, C., Hoang, L., & Rush, A. M. (2017). Structured Attention Networks. In ICLR.
http://jalammar.github.io/illustrated-transformer/
https://zhuanlan.zhihu.com/p/48508221